Data Science становится все более популярным направлением профессиональной деятельности. От специалиста в этой области требуются глубокие знания, а также навыки, «обкатанные» на практике.
Начинающие аналитики могут воспользоваться такими решениями, как Weka, имеющие уже заложенный мощный функционал. Тем не менее для специалистов data science требуется широта и маневренность действий, поэтому они создают собственные инструменты и пайплайны. И Python для этих целей подходит идеально.
Возможности этого языка позволяют создать приложение как с нуля, так и с помощью специально созданных для этого инструментов. И сегодня мы поговорим о том, что это за средства.
Библиотеки CSV, OpenPyXL для обработки больших массивов данных
Самыми популярными форматами данных, безусловно, являются .xlsx, .xlsm. Тем не менее, большое количество специалистов любит формат .csv. Это такие файлы, в каких каждая строка представлена полями, разделенными определенным знаком (как правило, запятой либо точкой с запятой).
Наиболее популярной библиотекой Python для обработки данных является Pandas. Ее основное преимущество в том, что она поддерживает самые разнообразные форматы файлов. Чтобы работать с файлами Excel, Pandas использует модули xlrd, xlwt.
Модуль CSV включает утилиты для обработки файлов формата CSV. Тем не менее особенности конкретных файлов этого формата могут разниться (например, в Excel). Это вызывает ряд сложностей в их обработке. Правда, не в случае с модулем CSV Pandas, который умеет правильно обрабатывать подавляющее количество реализаций .csv без надобности специально учитывать приложение, с помощью которого этот файл был создан.
OpenPyXL – это библиотека, с помощью которой можно работать с Excel-файлами. Она умеет работать исключительно с теми книгами, которые были созданы с помощью Excel 2010 и новее. С помощью OpenPyXL можно читать, записывать и обрабатывать данные форматов .xlsx, .xlsm, .xltx, .xltm. Модуль умеет не только читать, записывать и обрабатывать эти форматы, но и строить графики.
Примеры на практике
Давайте на реальных примерах рассмотрим эти инструменты. Нами будут использоваться данные с портала Kaggle об участниках Олимпийских игр за последние 120 лет.
Для начала необходимо считать данные.
import pandas as pd
data = pd.read_excel("athlete_events2.xlsx")
Либо
data2 = pd.read_csv("athlete_events.csv")
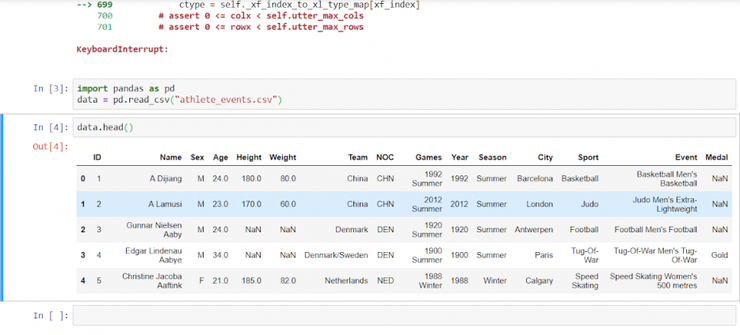
Получаем следующую таблицу.
data2.head()
Работать с ячейками можно и по определенному индексу.
data2.iloc[6]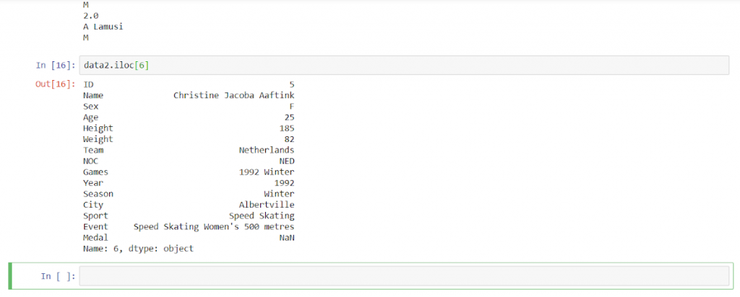
data2.iloc[[6]]]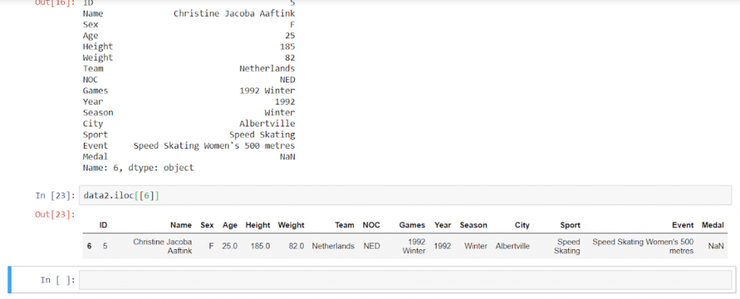
Либо по названию колонки.
data2[[‘Name’]]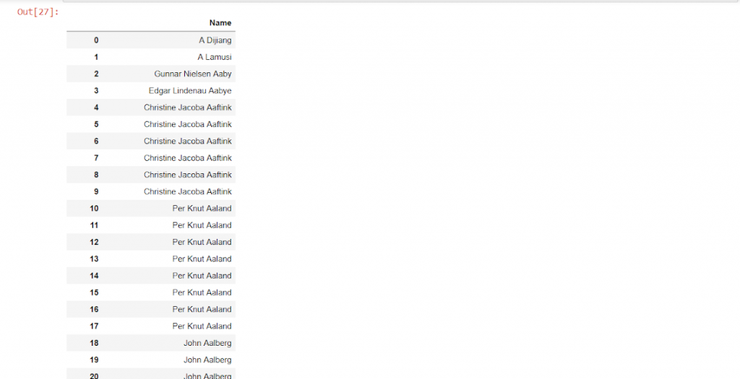
Несколько строк в Pandas выделяются с помощью двоеточия.
data2[3:7]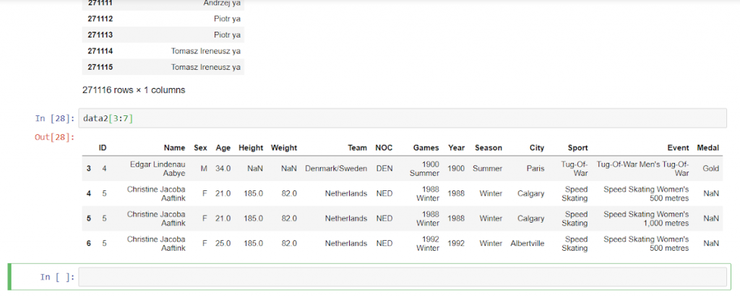
Теперь воспользуемся библиотеками CSV и OpenPyXL для открытия файлов.
import csv
with open('athlete_events.csv', 'r', newline='') as file:
data3 = csv.reader(file)
Тем не менее при таком считывании вывод нужно будет делать стандартным способом для Python. Или же можно подключать структуру data frame из Pandas. В нашем случае мы получим длинный текст следующего вида.
for row in data3:
print(','.join(row))
import openpyxl
open_data = openpyxl.load_workbook('athlete_events2.xlsx')
В переменной open_data содержится объект класса рабочей книги excel со всеми листами, которые там хранятся. С помощью метода open_data.get_sheet_names() мы можем получить названия листов, которые используются для обращения к нужным сведениям. В случае с нами информация доступна лишь на одном листе.
names = open_data.get_sheet_names () print(names)
Вследствие этого, мы получаем следующий результат.
['Лист1']
sheet = open_data.get_sheet_by_name('Лист1')
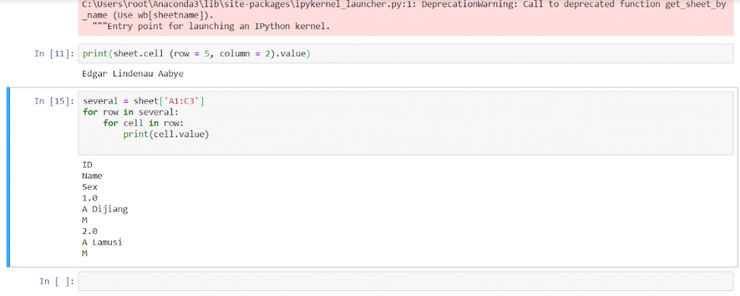
А теперь обратим внимание на значение ячейки, которая находится на пересечении второго столбца и пятой строки.
print(sheet.cell(row=5, column=2).value)
Результат
Edgar Lindenau Aabye
Возьмем диапазон ячеек этого листа и покажем значения.
several = sheet[‘A1:C3’] for row in several: for cell in row: print(cell.value)
 А теперь извлеченные файлы запишем в .xlsx и .csv.
А теперь извлеченные файлы запишем в .xlsx и .csv.
Pandas
data2.to_csv("new_file1.csv", sep= ',', index=False, header=False)
data2.to_excel("new_file2.xlsx", index=False)
CVS
with open("new_file3.csv", "w", newline='') as file:
writer = csv.writer(file, delimiter=';')
for line in data3:
writer.writerow(line)
OpenPyXL
open_data.save("new_file4.xlsx")
Matplotlib и Seaborn – Визуализация данных
Библиотека Matplotlib была создана Джоном Хантером для создания графиков и других способов визуализации данных. А Seaborn является «надстройкой» над Matplotib, которая предоставляет широкий спектр возможностей по визуализации данных.
Давайте рассмотрим использование этих библиотек на выборке из датасета об участниках олимпиады.
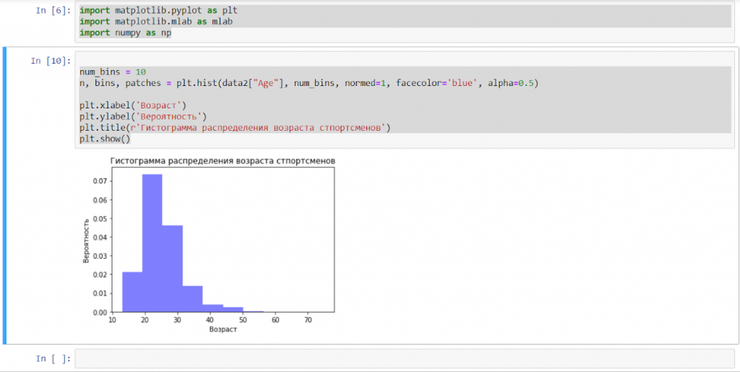
Для этого создадим гистограмму, содержащую данные о том, какого возраста участники олимпиады. Для этого будем использовать модуль Python numpy.
import matplotlib.pyplot as plt
import numpy as np
num_bins = 10
n, bins, patches = plt.hist(data2["Age"], num_bins, normed=1, facecolor='blue', alpha=0.5)
plt.xlabel('Возраст')
plt.ylabel('Вероятность')
plt.title(r'Гистограмма распределения возраста спортсменов')
plt.show()
И выполним аналогичные действия с использованием библиотеки Seaborn.
import seaborn as sns data2.Age.values sns.distplot(data2.Age.dropna())
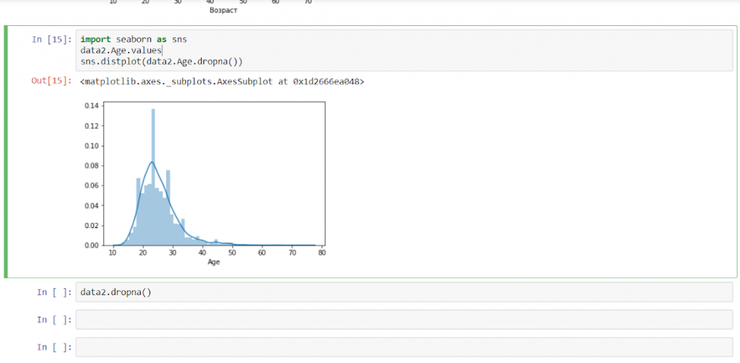 Как мы можем понять из фрагмента кода выше, библиотека Seaborn делает код гораздо более лаконичным. К тому же, distplot включает большое количество параметров по умолчанию. Один из них – построение кривой распределения (синяя линия на последнем графике), в то время как Matplotlib требует того, чтобы ее отдельно задавать. В свою очередь, это требует еще нескольких дополнительных строк кода, а также импорта дополнительного модуля из библиотеки.
Как мы можем понять из фрагмента кода выше, библиотека Seaborn делает код гораздо более лаконичным. К тому же, distplot включает большое количество параметров по умолчанию. Один из них – построение кривой распределения (синяя линия на последнем графике), в то время как Matplotlib требует того, чтобы ее отдельно задавать. В свою очередь, это требует еще нескольких дополнительных строк кода, а также импорта дополнительного модуля из библиотеки.
С другой стороны, Matplotlib – гораздо более маневренное решение в плане параметров базового графика и его стиля. Поэтому очень часто Seaborn и Matplotlib используются вместе.
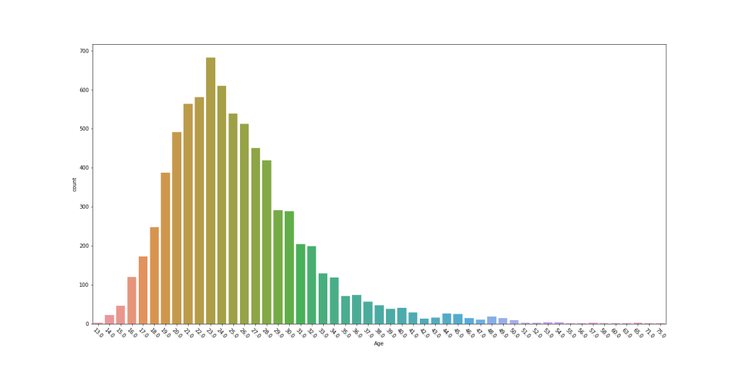
plt.figure(figsize=(20, 10))
sns.countplot(x=data2.Age, data=data2)
plt.xticks(rotation=-45)
plt.savefig("plot.png")
Машинное обучение в Python
Для реализации машинного обучения в Python используется библиотека SciKit-Learn, в которую включены различные методы классификации, регрессии и кластеризации, а также нейросетей. SciKit предоставляет большой выбор инструментов для решения проблемы размерности данных, сравнения моделей машинного обучения и их производительности, а также для извлечения важных признаков.
Рассмотрим реализацию линейной регрессии, например, чтобы проверить версию о корреляции веса и возраста участника олимпийских игр.
from sklearn.linear_model import LinearRegression import numpy as np
После импорта требуемых библиотек необходимо избавиться от значений типа NA. Наиболее простой способ это сделать – удалить строки, в которых NA присутствуют. Правда, есть варианты получше, но правильно упростить задачу для новичков.
data2 = data2.dropna(axis=0)
Для модели, зависимость значений в которой мы ходим проанализировать, зададим переменные.
x = np.array(data2.Age.values) y = np.array(data2.Weight.values) x = x.reshape((-1, 1))
Теперь построим модель.
model = LinearRegression() model.fit(x, y) model = LinearRegression().fit(x, y)
И определим коэффициент линейной регрессии для оценки эффективности модели.
r_sq = model.score(x, y)
print('coefficient of determination:', r_sq)
Результат получаем следующий.
coefficient of determination: 0.024385595989105727
Коэффициент детерминации у нас получился очень низким, поскольку его минимальное значение должно быть хотя бы 0,5. Следовательно, либо мы неправильно провели предварительную обработку данных (что верно, поскольку нами не учитывался разброс данных и другие характеристики), либо линейная регрессия неприменима к данному случаю. Последний вариант возможен в тех ситуациях, когда возраст и вес спортсменов не связаны между собой.
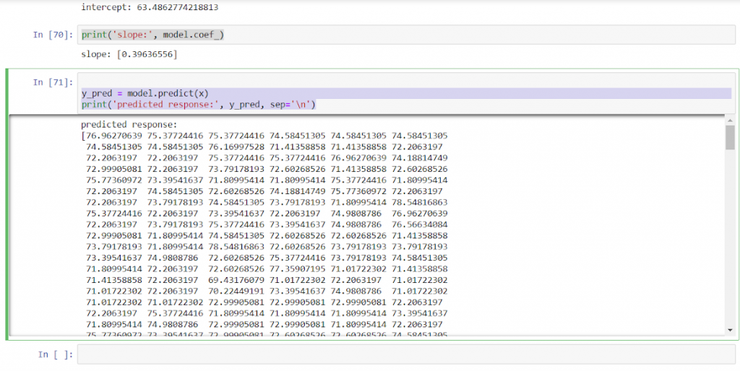
Для наглядности мы можем предсказать значение веса по возрасту, но не стоит доверять этой модели.
y_pred = model.predict(x)
print('predicted response:', y_pred, sep='\n')
Генераторы и Lambda-функции
На первый взгляд, эти инструменты могут путать новичков в программировании на Python. Тем не менее они полезны в любой из областей разработки приложений. И data science – не исключение. Новички нередко недооценивают эффективность данных методов.
Каждый человек, который хотя бы раз пытался запрограммировать последовательность действий, понимает, что для этого используется цикл for либо while.
Например, стандартная реализация заполнения списка символами из строки Python будет выглядеть следующим образом.
string = "123456erert,42,;432EkRRPPEW254" spisok = [] for el in string: y = el*2 spisok.append(y) print(spisok)
В результате, мы получим следующую последовательность значений.
[’11’, ’22’, ’33’, ’44’, ’55’, ’66’, ‘ee’, ‘rr’, ‘ee’, ‘rr’, ‘tt’, ‘,,’, ’44’, ’22’, ‘,,’, ‘;;’, ’44’, ’33’, ’22’, ‘EE’, ‘kk’, ‘RR’, ‘RR’, ‘PP’, ‘PP’, ‘EE’, ‘WW’, ’22’, ’55’, ’44’]
С помощью генераторов у нас появляется возможность записать эту операцию в одну строчку.
spisok = [el*2 for el in string] print(spisok)
И теперь мы получаем такой же результат, но с помощью значительно меньшего количества строк кода.
[’11’, ’22’, ’33’, ’44’, ’55’, ’66’, ‘ee’, ‘rr’, ‘ee’, ‘rr’, ‘tt’, ‘,,’, ’44’, ’22’, ‘,,’, ‘;;’, ’44’, ’33’, ’22’, ‘EE’, ‘kk’, ‘RR’, ‘RR’, ‘PP’, ‘PP’, ‘EE’, ‘WW’, ’22’, ’55’, ’44’]
Генераторы довольно полезны и удобны и для более сложных примеров.
Задача lambda-функций аналогичная – сделать код меньше для функций. В той ситуации, если она содержит одну операцию либо одно общее выражение, лямбда-конструкция дает возможность не создавая функцию выполнить последовательность действий, аналогичную функции. Да, это может показаться несколько запутанным, поэтому разберем элементарный пример. Предположим, необходимо определить количество элементов списка.
def elements(list1): return len(list1) print(elements(spisok))
Результат.
30
Теперь выполним аналогичные действия с использованием лямбда-функции.
elements = lambda x: len(x) print(elements(spisok))
Результат получаем такой же.
30
Нами были рассмотрены лишь 8 средств Пайтон: и профессиональные библиотеки, и инструменты, которые могут быть использованы любым разработчиком для того, чтобы грамотно взаимодействовать с данными.













