Переходим ко второму уроку по Pandas. Сегодня поговорим более подробно об особенностях выполнения агрегации данных, а также их группировке. В аналитике эти методы используются повсеместно, поэтому необходимо в деталях разобраться в особенностях их использования.
Внимание! Поскольку это – практическое руководство, то рекомендуется не копировать код, а писать его самостоятельно. А потом читать инструкции для того, чтобы понять, как он работает. Или параллельно читая инструкции, кому как удобнее.
- Теоретические аспекты агрегации данных
- Практические аспекты агрегации данных
- Использование метода countдля агрегации данных pandas
- Использование метода .sum()для агрегации данных
- Использование функций .min()и .max() для агрегации базы данных
- Использование функций .mean()и .median() для агрегации данных
- Использование группировки в Pandas
- Как работать с функцией groupby?
- Тестовые задания
- Проверка №2
- Выводы
Теоретические аспекты агрегации данных
Под агрегацией подразумевается превращение значений набора данных в одно единое. Предположим, у вас есть такой набор информации.
| animal | water_need |
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
В этом случае наиболее простым способом агрегации служит суммирование water_needs. Проще говоря, необходимо сложить значения 100 + 350 + 670 + 200. В результате, получится значение 1320.
Также возможен подсчет количества животных – 4. Теория не так сложна. Тем не менее, практика может быть сопряжена с определенными нюансами, которые необходимо рассмотреть более подробно.
Практические аспекты агрегации данных
На каком месте мы остановились в прошлый раз? Открыли Jupyter Notebook, осуществили импорт Pandas, Numpy, а также загрузили два набора данных: zoo.csv, article_reads. Давайте теперь продолжим на этом же месте. Если вами ранее не была пройдена первая часть, то рекомендуется ее прочитать.
Начнем с набора zoo. Его загрузка была осуществлена следующим образом.
pd.read_csv('zoo.csv', delimiter = ',')
Теперь давайте попробуем сохранить набор с данными в переменную zoo.
zoo = pd.read_csv('zoo.csv', delimiter = ',')
Далее пять шагов надо выполнить:
- Определить общее количество строк (то бишь, количество животных) в zoo.
- Определить общее значение water_need животных.
- Понять, какое значение water_need в этой базе данных самое маленькое.
- Какое из них самое большое.
- И какое среднее.
Использование метода count для агрегации данных pandas
Чтобы определить количество животных, необходимо воспользоваться функцией count, которая вызывается, как метод объекта zoo.
zoo.count()

А что это за строчки? На самом деле, с помощью функции count() мы определили количество значений в каждой из колонок. В случае с zoo у нас было всего лишь три колонки. В каждой из них 22 значения. Чтобы вывод стал более понятным, можно выбрать столбец animal, используя оператор выбора из предыдущего материала.
zoo[['animal']].count()
Тогда результат будет даже лучше.
Использование метода .sum() для агрегации данных
По аналогичной логике, можно легко определить сумму значений water_need, используя следующую строку кода.
zoo.water_need.sum()

А если надо определить сумму значений во всех колонках, это делается с помощью такой функции.
zoo.sum()

Использование функций .min() и .max() для агрегации базы данных
Чтобы определить минимальное значение, которое есть в колонке water_need(), необходимо использовать функцию .min(), как на этом фрагменте кода.
zoo.water_need.min()
Для того, чтобы определить максимальное значение, соответственно, используется функция .max().
Использование функций .mean() и .median() для агрегации данных
В конечном итоге, нам необходимо определить среднестатистические показатели. Например, среднее и медиану. Для этого используются, соответственно, функции mean() и median().
zoo.water_need.mean() zoo.water_need.median()
Как видим, агрегация данных в SQL сложнее, чем в Pandas.
Тем не менее, можно использовать группировку, и тогда будет чуточку сложнее. Правда, не сильно.
Использование группировки в Pandas
При работе в сфере Data Science постоянно придется заниматься сегментациями данных. Например, понадобится знать количество необходимой воды для всех животных. И здесь хорошо было бы осуществить разбивку по тому, какие именно животные.
Мы рассмотрим особенности сегментации на основе значений и колонок. В частности, для этого можно использовать функцию .groupby.
Как работать с функцией groupby?
Теперь давайте попробуем попробуем сделать группировку с DataFrame zoo. Между переменной с таким же именем и функцией .mean() необходимо вставить ключевое слово groupby.
zoo.groupby('animal').mean()
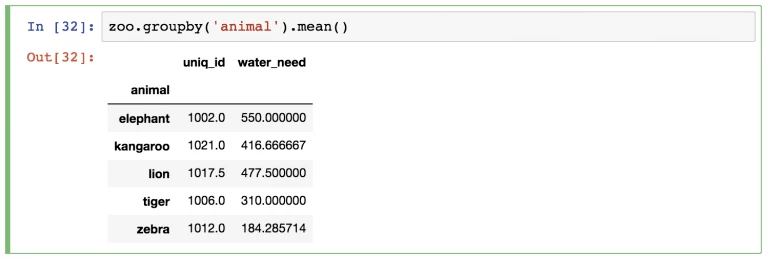
Точно так же, как и в описанных выше случаях, будет осуществляться автоматическая проверка .mean() для колонок, которые остались. Так, колонка animal исчезла, поскольку по ней проводилась группировка. Можно либо игнорировать колонку uniq_id либо убрать ее каким-либо из описанных методов.
zoo.groupby('animal').mean()[['water_need']] — возвращает объект DataFrame.
zoo.groupby('animal').mean().water_need — возвращает объект Series.
Можно использовать любой другой метод агрегации, который был описан ранее.
Тестовые задания
А теперь давайте попробуем подытожить изученный материал и проверить знания.
Внимание! Перед тем, как читать этот блок, необходимо скачать данные из блога о путешествиях.
Найти его можно по этой ссылке. Если все готово, то вот первое задание.
Какой источник применяется чаще, чем все другие в article_read?
Конечно, же, Reddit. Чтобы его получить, необходимо было воспользоваться таким кодом.
article_read.groupby('source').count()
То есть, наша последовательность действий была следующей:
- Сначала мы взяли набор данных article_read, создали сегменты по значениям столбца source (groupby(‘source’)).
- А в конечном итоге определить значения по источникам .count().
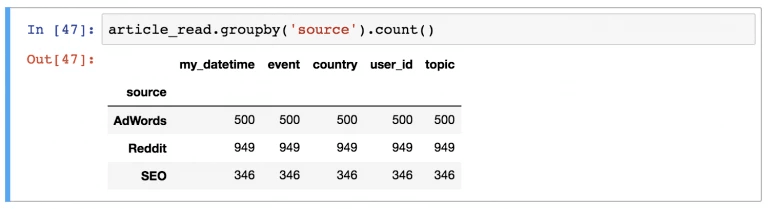
Помимо этого, можно убрать колонки, которые не подходят, оставив исключительно user_id.
article_read.groupby('source').count()[['user_id']]
Проверка №2
А теперь попробуйте, воспользовавшись скачанным ранее набором данных, ответить на следующий вопрос.
Какая страна и источник для пользователей country_2 являются наиболее востребованными. Проще говоря, какая тема из какого источника смогла обеспечить максимальное количество просмотров из country_2?
Итак, правильный ответ: Reddit, Азия. Всего 139 прочтений.
Чтобы получить результат, необходимо использовать следующий Python-код.
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count()
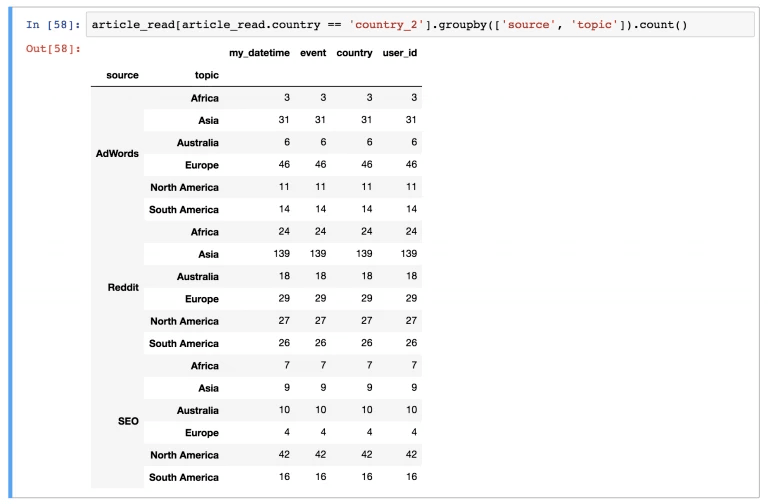
А теперь объясним принцип решения этой задачи. Сначала осуществлялась фильтрация юзеров из country_2 (article_read[article_read.country == ‘country_2’]). После этого, по отношению к данному подмножеству был применен метод groupby.
Да, возможна группировка для более, чем одной колонки. Для этого, надо создать список названий. Именно по этой причине мы использовали квадратные скобки внутри круглых.
Это по поводу части groupby([‘source’, ‘topic’]).
А что касается функции count(), то она просто выполняет роль заключительного элемента.
Выводы
Таким образом, мы разобрали, как выполнять агрегацию и группировку в pandas. Мы видим, что эти операции довольно простые, но их надо часто использовать.
При этом надо учитывать, что приступать к изучению pandas рекомендуется через некоторое время после того, как был изучен SQL, если эти базы данных изучаются вместе. Дело в том, что так легче их будет сравнивать между собой. К слову, попробуйте сравнить методы агрегации в них. Это поможет понять разницу между логикой каждого из языков.
Конечно, это не все, что нужно знать для обработки данных. Необходимо уметь правильно их форматировать. А для этого используется набор функций. Но об этом стоит поговорить отдельно.
И пару слов о самой профессии. Аналитика данных сейчас становится все более востребованной. Все потому, что сейчас век информации. И каждому известна поговорка «кто владеет информацией, тот владеет миром». Но важно не только владеть информацией, но и уметь ее анализировать, а также строить точные прогнозы, основываясь на этих данных. Соответственно, специалисты, которые с помощью компьютерных программ это будут уметь делать, высоко ценятся на рынке труда.
Они легко смогут найти себе работу в любой отрасли, начиная розничной торговлей и заканчивая астрофизикой.
В спектр обязанностей специалиста по Data Science входит:
- Построение и тестирование математических моделей данных.
- Поиск закономерностей в имеющейся информации с дальнейшей возможностью прогнозировать будущие значения. Например, исходя из спроса на товары в прошлом, дата-сайентист поможет компании понять, как при текущих вводных будут выполняться планы продаж в следующем году и будут ли вообще.
Data Science нужен в любых сферах, где имеются большие объемы данных. Поскольку методы работы с данными универсальны, для специалистов открыты все области: от розничной торговли и банковского дела до метеорологии и химии. В науке они помогают делать важные открытия: проводить сложные исследования. Например, создание и обучение нейронных сетей для молекулярной биологии, изучение гамма-лучей или выполнение анализа ДНК.
В крупных компаниях специалист по данным — это тот, кто нужен всем отделам: именно он может помочь маркетологам проанализировать данные карт лояльности и понять, какие группы клиентов следует рекламировать.
Для логистов будет полезным изучение данных с GPS-трекеров и оптимизация транспортного маршрута.
Отдел кадров может предсказать, кто из сотрудников скоро уйдет, проанализировав их активность в течение рабочего дня и ряд других факторов.
Как видим, специалист по Data Science всегда может, где себя применить. Поэтому обязательно изучайте анализ данных, поскольку это перспективно и выгодно. Успехов.













