Data Science – популярное направление разработки приложений, в котором можно неплохо зарабатывать. И чтобы работать с данными, необходимо использовать специальную библиотеку, предназначенную для этого. Одной из самых популярных из них является Pandas. Некоторые ее сравнивают с SQL для Python. Все потому, что Pandas работает на основе двухмерных таблиц данных. Есть также ряд других особенностей. Сегодня вы узнаете основы аналитики данных с использованием этой библиотеке.
Настоятельно рекомендуется самостоятельно писать весь код, который будет указан ниже в качестве примера. Все потому, что это практическое руководство. Надо не копировать, а именно переписывать самостоятельно.
- Что нужно?
- Открытие файла данных в Pandas
- Структуры данных в Python
- Как загрузить .csv-файл в DataFrame?
- Как осуществлять отбор данных из базы в Pandas?
- Вывод всего Dataframe
- Как осуществлять вывод части Dataframe?
- Как вывести конкретные колонки из таблицы?
- Как осуществить фильтрацию значений в таблице?
- Использование функций одна за другой
- Выводы
Что нужно?
Изначально надо иметь версию Python хотя бы 3,7. Можно более новую. Помимо этого, должны быть установлены numpy, Pandas.
Далее надо подключиться к серверу. Если его нет, то можно создать локальный сервер, после чего запустить Jupyter. После этого открыть браузер, который подходит вам больше всего и открыть Jupyter Notebook. Далее создается ноутбук с названием pandas_tutorial_1.
Далее надо импортировать numpy, pandas в Jupyter Notebook с использованием двух строчек кода.
import numpy as np import pandas as pd
Внимание! Чтобы обратиться к библиотеке, можно также воспользоваться аббревиатурой pd. Если в конце инструкции с import имеются as pd, Jupyter Notebook понимает, что в будущем, при вводе этих двух букв необходимо обратиться именно к библиотеке Pandas.
Теперь все настроено. Поэтому переходим к руководству по этой библиотеке. Начнем с вопроса, как правильно осуществлять открытие файлов с информацией с помощью этой библиотеки.
Открытие файла данных в Pandas
Хранение данных возможно в таблицах SQL либо в CSV-таблицах. Также есть вариант использования других форматов, в том числе, и Excel. Тем не менее, цель одинаковая. необходимо иметь структуру данных, которая будет совместимой с pandas.
Структуры данных в Python
Таких структур данных в Pandas есть две: Series и DataFrame.
Под первой подразумевается одномерная структура данных. В этом случае каждое значение имеет свой уникальный индекс. 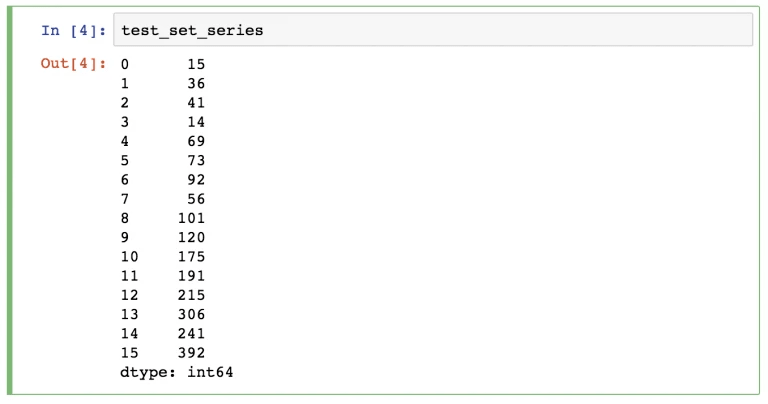
А DataFrame уже считается двухмерной структурой. Это означает, что она состоит из колонок и строк. Каждый столбец имеет свое имя, а строка – индекс.
Выглядит такая структура данных следующим образом.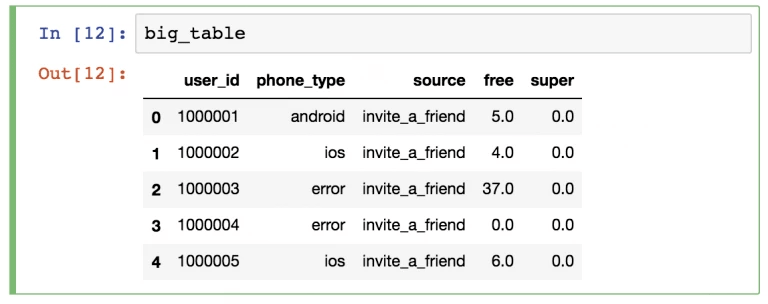
Сегодня мы более подробно будем рассматривать второй вариант. Почему? Дело в том, что обработку большей части информации значительно проще осуществлять в двухмерной структуре.
Как загрузить .csv-файл в DataFrame?
Чтобы это сделать, необходимо использовать функцию read_csv(). Давайте начнем с образца, называющегося zoo. В этом случае вам надо создать этот файл самостоятельно. Сырые данные следующие.
animal,uniq_id,water_need elephant,1001,500 elephant,1002,600 elephant,1003,550 tiger,1004,300 tiger,1005,320 tiger,1006,330 tiger,1007,290 tiger,1008,310 zebra,1009,200 zebra,1010,220 zebra,1011,240 zebra,1012,230 zebra,1013,220 zebra,1014,100 zebra,1015,80 lion,1016,420 lion,1017,600 lion,1018,500 lion,1019,390 kangaroo,1020,410 kangaroo,1021,430 kangaroo,1022,410
Теперь вернем ко вкладке Home Jupyter, чтобы сгенерировать новый текстовый файл. 
После этого выполняем копирование информации выше, чтобы вставить данные в этот файл.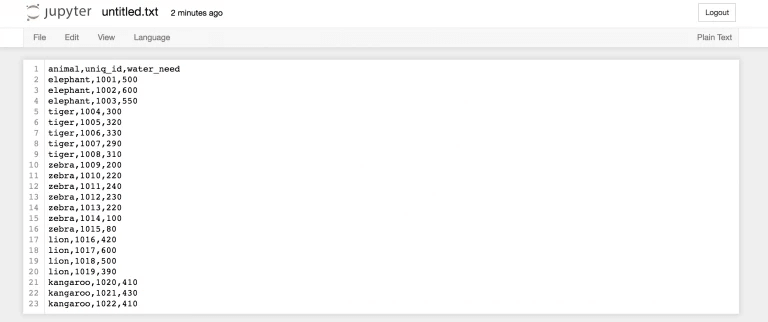
И в конечном итоге, называем его zoo.csv.
Это и будет первый csv-файл.
Теперь давайте вернемся в Jupyter Notebook с именем pandas_tutorial_1, чтобы открыть в нем этот файл. Чтобы это сделать, необходимо воспользоваться функцией read_csv().
Для этого вводим такую инструкцию.
pd.read_csv('zoo.csv', delimiter=',')
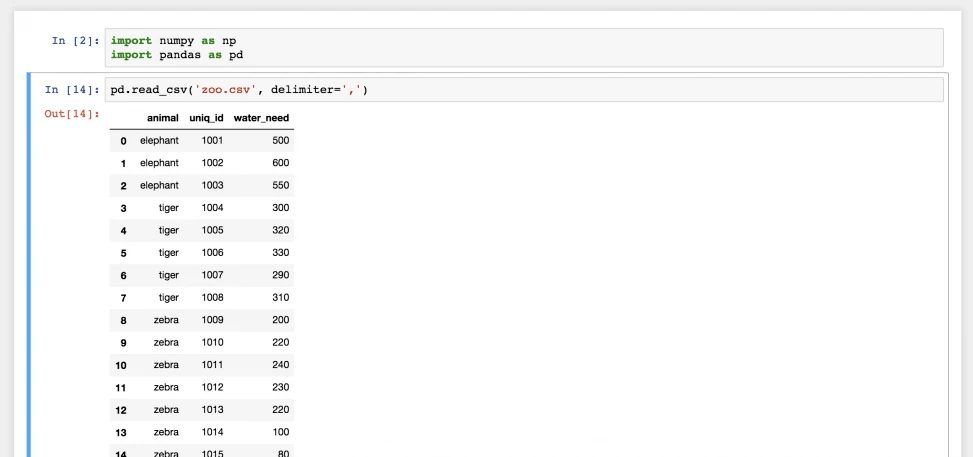
Все, теперь файл zoo.csv был перенесен в pandas и стал двухмерной таблицей DataFrame. Слева расположены индексы, а источником для названий столбцов вверху служит первая строка файла zoo.csv.
На самом деле, вам вряд ли придется создавать этот файл для себя, поскольку будут уже готовые файлы с данными, которые надо будет обрабатывать. Просто необходимо понимать, как осуществлять их загрузку на сервер. Если нажать по ссылке, файл с данными загрузится на ПК. Но он ведь не нужен там. Ведь его надо сначала выгрузить на сервер, а потом и в Jupyter Notebook. Для этого потребуется два действия:
- Вернуться в Jupyter Notebook и указать следующую команду.
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv
Таким образом будет загружен файл pandas_tutorial_read.csv на сервер. При клике по нем появляется возможность получить все данные из файла. - Вернуться в Jupyter Notebook и применять ту же функцию read_csv (не забыв сменить название файла и разделитель).
pd.read_csv(‘pandas_tutorial_read.csv’, delimete=’;’)
После этого загрузка данных в pandas считается окончательно завершенной.
В итоге, у нас получится такая таблица.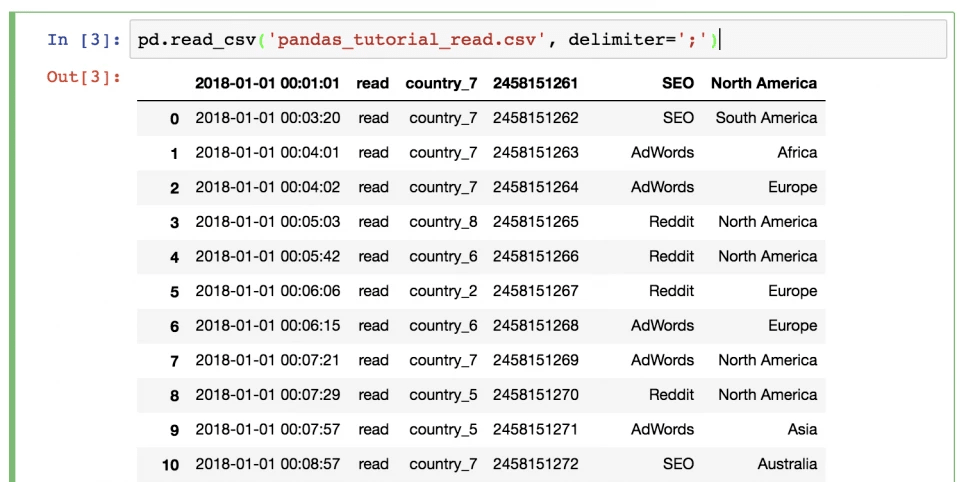
Здесь видим определенную проблему. На этот раз отсутствует заголовок, поэтому его настройку нужно выполнить самостоятельно. Для этого надо добавить в функцию параметры имен.
pd.read_csv('pandas_tutorial_read.csv', delimiter=';',
names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])
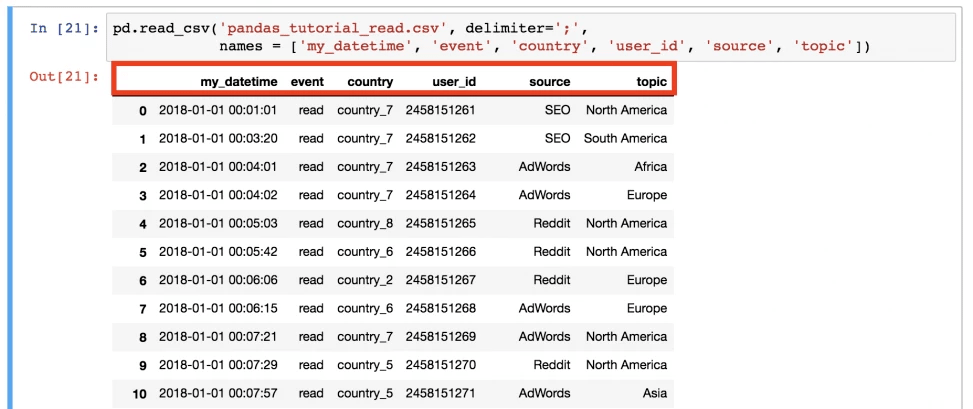
Видим, что такой вариант лучше. Теперь файл .csv загружен в pandas DataFrame уже окончательно.
При этом есть и альтернативный метод. Загрузка файла с данными возможна и напрямую через адрес URL. В этом случае загрузки информации на сервер не будет.
А на практике это выполняется следующим образом. Напишите такой код.
pd.read_csv( 'https://pythonru.com/downloads/pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )
Если вам интересно, что в этом наборе, то это набор информации о путешествиях из специализированного блога. Ну а о том, какие сведения хранятся в колонках, очевидно из самой таблицы.
Как осуществлять отбор данных из базы в Pandas?
Начнем с самых простых вариантов, а потом уже перейдем к разбору более сложных.
Вывод всего Dataframe
Стандартный метод – осуществлять вывод всех данных из Dataframe на экран. Для этого нет необходимости в том, чтобы запускать функцию pd.read_csv() каждый раз. Достаточно просто сохранить сведения в переменную при чтении.
article_read = pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )
Затем можно вызывать значение article_read для вывода данных таблицы уже каждый раз.
Как осуществлять вывод части Dataframe?
В некоторых случаях может понадобиться не выводить Dataframe целиком, заполнив экран данными, которые и не нужны в конкретной ситуации, а выбрать несколько строк, которые и будут выводиться. Например, первые 5 из них можно вывести следующим образом.
article_read.head()
Если же нужно вывести последние 5 строк, то это делается так.
article_read.tail()
Как вывести конкретные колонки из таблицы?
А это уже более сложная задача. Допустим, необходимо поставить на вывод исключительно колонки country и user_id. Что в этом случае нужно делать? Использовать такую команду.
article_read[['country', 'user_id']]
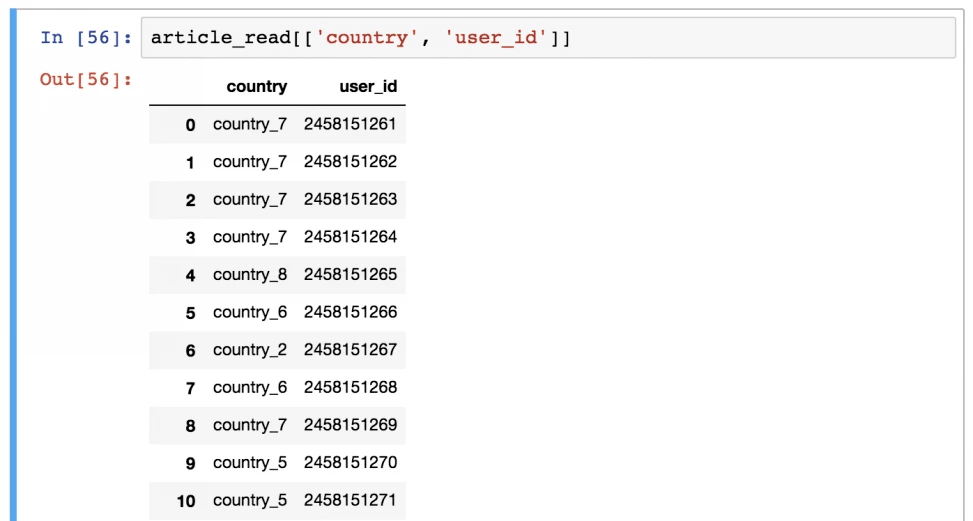
А теперь вопрос: зачем здесь используются двойные квадратные скобки? На первый взгляд, ответ может быть довольно сложным, но логика, на самом деле, проста. Внешние скобки уведомляют pandas, что вы хотите выбрать колонки, а внутренние являют собой список. Да, самый обычный стандартный список Python, который всегда указывается в квадратных скобках.
Если мы заменим порядок имен колонок, результат вывода также будет другим. Это DataFrame выбранных колонок.
Внимание! В некоторых случаях необходимо получить доступ к объектам Series. Чтобы это сделать, есть один из следующих методов.
article_read.user_id article_read[‘user_id’]
Как осуществить фильтрацию значений в таблице?
Этот шаг более сложный. Допустим, необходимо сохранить исключительно пользователей, представленных в источнике «SEO». Чтобы это сделать, надо выполнить фильтрацию по соответствующему значению. Для этого используется такая инструкция.
article_read[article_read.source == 'SEO']
Использование функций одна за другой
Необходимо учитывать и то, что у Pandas логика линейная (точно такая же, как и в SQL). Следовательно, если вы применяете функцию, то возможно к ней применение другой же. В этом случае входящие данные последней функции будут выводом предыдущей. Например, давайте попробуем соединить эти два метода перебора.
article_read.head()[['country', 'user_id']]
С помощью первой строчки мы выбираем первые 5 строк из набора данных. Затем она выбирает колонки «country» и «user_id».
Есть ли возможность получения такого же результата, но используя другую цепочку функций? Конечно же!
article_read[['country', 'user_id']].head()
Здесь сначала осуществляется выбор колонок, а затем берутся первые 5 строк. В результате, будет то же самое, просто будет отличаться порядок функций и особенности их выполнения.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv()?
pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )[['country', 'user_id']].head()
Поэтому важно учитывать, что использование этой библиотеки подразумевает применение функций и методов последовательно, и ничего более.
Выводы
Таким образом, работать с Pandas не так сложно. Для начинающего data-scientist-а это очень простой инструмент, который при этом достаточно функциональный.













