Продолжаем изучать библиотеку Pandas, которая позволяет выполнять обработку данных. Сегодня поговорим о том, как правильно осуществлять форматирование данных. В частности, тех, которые чаще всего используются в проектах data science: merge, sort, reset_index, fillna. Конечно, есть и другие типы данных, но мы сделаем сегодня акцент на тех, которые являются наиболее популярными.
Внимание! Поскольку это практическая инструкция, то рекомендуется самостоятельно писать код, а не просто копировать его. Это поможет значительно ускорить процесс обучения.
Merge в pandas
С помощью этой функции мы можем объединять Data Frames, содержащих различную информацию. В реальных проектах информация, как правило, не хранится в одной таблице. Вместо нее используется большое количество небольших. Почему? Все потому, что несколькими таблицами управлять значительно проще, легче избегать «многословия», есть возможность экономить дисковое пространство, а запросы к таблицам значительно быстрее обрабатываются.
Но при работе с информацией нередко приходится вытаскивать данные из нескольких таблиц. Для того, чтобы реализовать эту задачу на практике, используется функция merge.
Несмотря на то, что эта функция называется по-другому, она по своему принципу работы почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo, который мы рассматривали ранее. Это база данных различных животных. Но в этот раз необходимо взять еще один zoo_eats. В нем будут содержаться данные о том, какую еду предпочитает каждое из животных.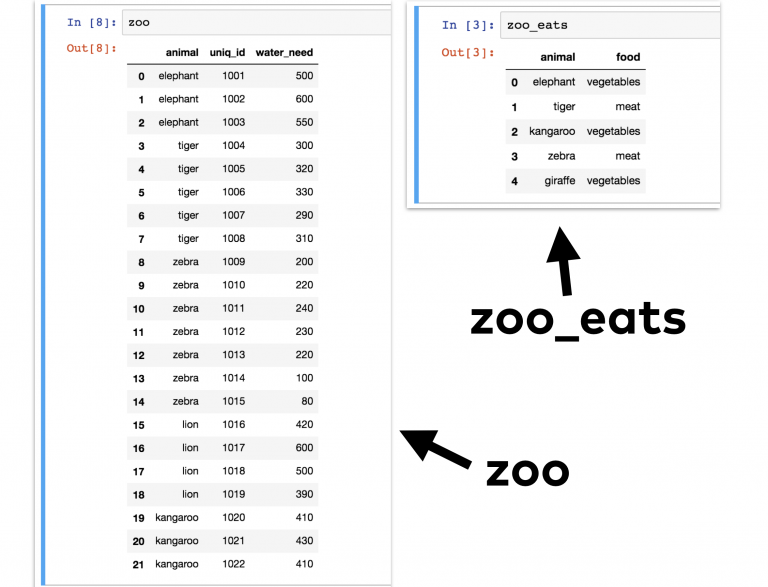
Теперь наша задача следующая: необходимо объединить эти датафреймы между собой. Конечный результат должен получиться следующим.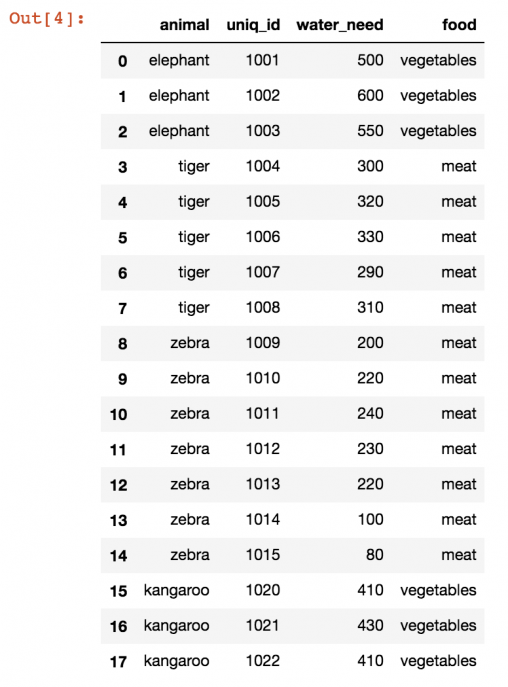
В этой таблице можно получить информацию типа того, какое количество животных из этой базы употребляют мясо либо овощи в пищу.
Как делается merge?
Сперва необходимо создать DataFrame zoo_eats, поскольку zoo уже ранее нами был создан в предыдущих частях. Чтобы сделать задачу проще, у нас есть такие данные.
animal;food elephant;vegetables tiger;meat kangaroo;vegetables zebra;vegetables giraffe;vegetables
Ранее мы уже рассказывали о том, что сделать для превращения этого набора данных в Pandas DataFrame. Но есть еще один метод, которым может воспользоваться тот человек, которому очень жаль времени и сил на выполнение большого количества излишних действий.
Достаточно лишь скопировать эту длинную строчку в Jupyter Notebook pandas_tutorial_1, созданный еще в первой части руководства.
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food'])
На этом создание DataFrame zoo_eats закончено. У нас получается приблизительно такой результат.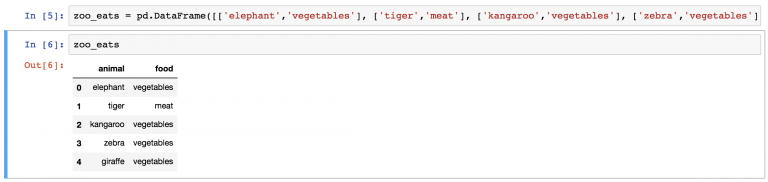
Теперь необходимо использовать наш метод merge для объединения этих таблиц.
zoo.merge(zoo_eats)
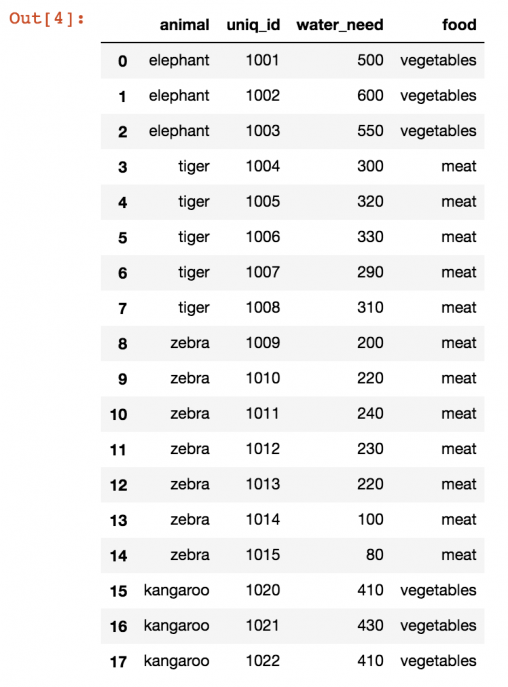
Как видим, реализовать эту задачу на практике не так сложно, как может показаться на первый взгляд. Но давайте рассмотрим совершенные действия более подробно.
Сначала мы указали первый DataFrame (zoo). Затем к нему мы применили метод merge() (Не забываем, что метод – это разновидность функции, которая относится к объекту и вызывается из него с помощью точки). В качестве параметра этой функции мы использовали DataFrame (zoo_eats), который был нами создан на предыдущем этапе.
В принципе, для объединения данных можно использовать и обратную функцию, используя зоопарк в качестве параметра, а вызвать метод из новосозданной в этом уроке таблицы.
zoo_eats.merge(zoo)
Разницы между этими вариантами не будет. Если не считать того, что порядок колонок в финальной таблице будет несколько иным.
Как задать способ объединения?
Базовый метод merge довольно легок в использовании. Тем не менее, иногда может понадобиться более гибкая его настройка. Один из наиболее важных вопросов – каким именно способом осуществлять объединение двух таблиц. Насколько вы можете знать, если вы изучали SQL, есть 4 способа объединения.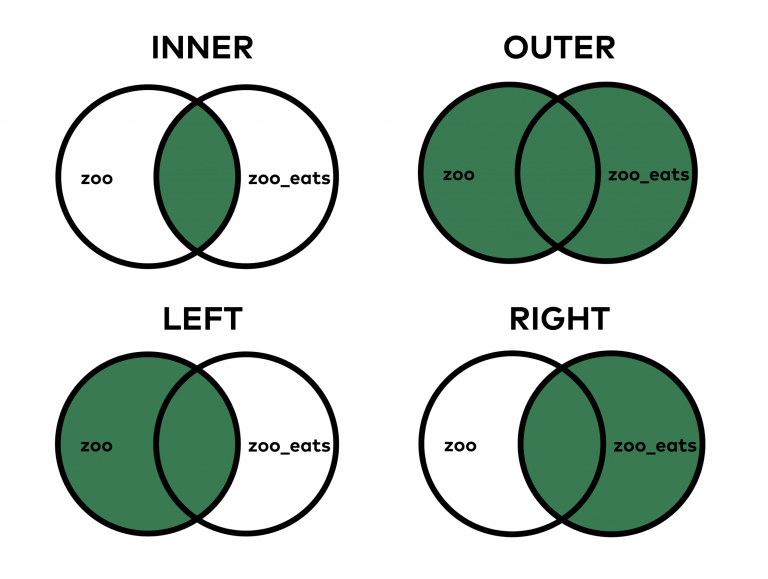
Если говорить о функции merge в pandas, все работает точно таким же образом.
Когда мы выбираем INNER JOIN (вид по умолчанию в SQL и pandas), выполняется объединение исключительно тех значений, которые можно найти в обеих таблицах. В случае же с OUTER JOIN, соединяются между собой абсолютно все значения. Да, даже если ряд из них находится в одной и той же таблице.
Давайте теперь приведем конкретный пример. В таблице zoo_eats у нас нет значения lion. А в zoo отсутствует giraffe. По умолчанию применялся метод INNER. Следовательно, и львы, и жирафы в итоговую таблицу не попали. Но в некоторых случаях нужно, чтобы все значения были в объединенной таблице с данными.
Чтобы это сделать, необходимо задать способ объединения OUTER. Это делается таким образом.
zoo.merge(zoo_eats, how='outer')
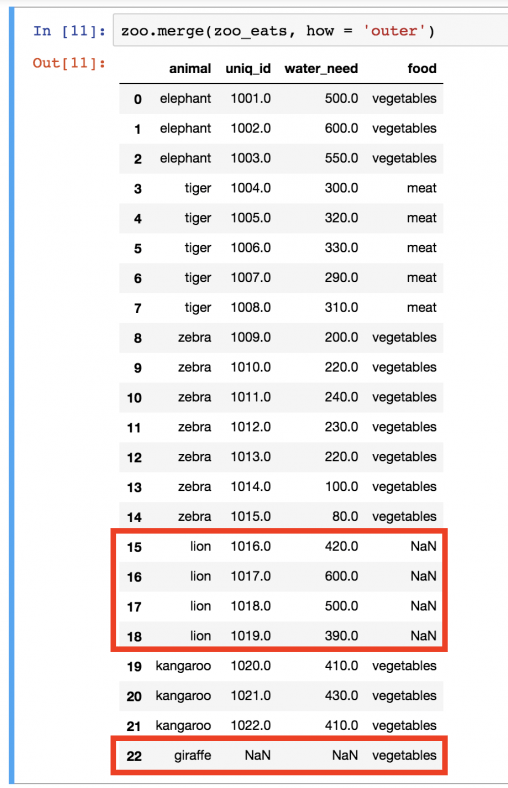
На этот раз мы вернули и жирафов, и львов. Но, так как вторая таблица не предоставила никакой информации, то в этом случае вместо значения мы увидим пропуск (NaN).
Логичнее всего было бы оставить львов в таблице, а вот жирафов исключить в нее. В этом случае будет три типа еды – растения, мясо и NaN (что означает отсутствие какой-либо информации). Если же в таблице останутся жирафы, это может запутать, так как в зоопарке же нет этого животного. Для того, чтобы решить эту проблему, необходимо при объединении использовать параметр how=’left’.
То есть, как приводится в этом фрагменте кода.
zoo.merge(zoo_eats, how='left')
Теперь в нашей таблице есть вся информация, которая нам нужна, и больше ничего. how = ‘left’ заберет все значения, содержащиеся в таблице с зоопарком, но из той, в которой приводится информация о еде, будет использовать исключительно те значения, которые имеются в левой.
Давайте повторно попробуем взглянуть на типы объединения.
Очень много пользователей интересуются: какой метод объединения из приведенных на этой картинке – наиболее безопасный? Тем не менее, однозначно на него ответить не получится. Все зависит от задачи, которая стоит в конкретный момент.
По какой колонке осуществляется объединение?
Для использования приведенной выше функции, необходимо наличие ключевых колонок, на которые и будет ориентироваться интерпретатор Python при объединении. В случае с нашим примером, такой колонкой служит animal. Но в некоторых случаях Pandas испытывает определенные затруднения в том, чтобы автоматически их распознать. В этом случае необходимо указывать названия колонок. Для этого используются параметры left_on и right_on.
Например, последний merge мог бы быть таким.
zoo.merge(zoo_eats, how = 'left', left_on='animal', right_on='animal')
В описанном примере выше pandas смог автоматически найти требуемые ключевые колонки. Но в некоторых случаях это может не произойти. Поэтому не рекомендуется забывать о том, чтобы указывать left_on и right_on.
Merge в pandas – довольно сложный в использовании метод, но в остальных случаях нам будет значительно проще.
Как выполнять сортировку в Pandas?
Без сортировки не может обойтись ни одна обработка данных. Базовый метод сортировки в pandas вовсе не вызывает никаких сложностей. Функция называется sort_values(), и она работает таким образом.
zoo.sort_values('water_need')

Внимание! Ранее в pandas мы использовали функцию sort(), которая работает аналогичным образом. Но в последних версиях она была на ту, которую мы привели сейчас. Поэтому использовать желательно именно ее, чтобы не возникло проблем с совместимостью с более новыми версиями.
В этом случае используется лишь параметр с названием колонки, water_need в нашем случае. Нередко приходится выполнять сортировку, основываясь на данных нескольких колонок. В этом случае для них необходимо использовать ключевое слово by.
zoo.sort_values(by=['animal', 'water_need'])

При этом описанное ключевое слово может быть использовано и для одной колонки zoo.sort_values(by = [‘water_need’].
sort_values сортирует в порядке возрастания, но это можно изменить на убывание:
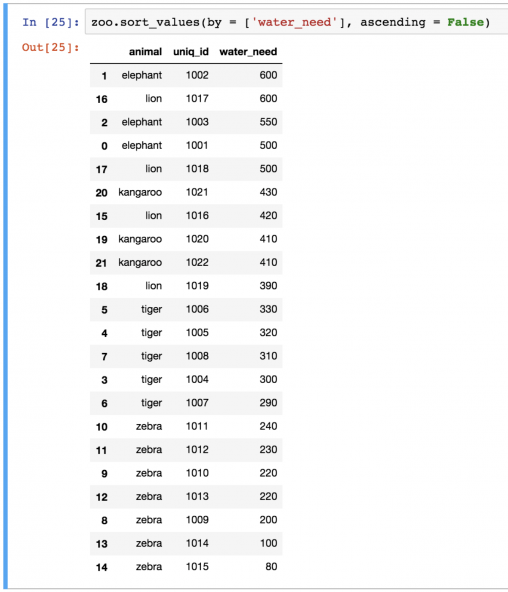
zoo.sort_values(by=['water_need'], ascending=False)
reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?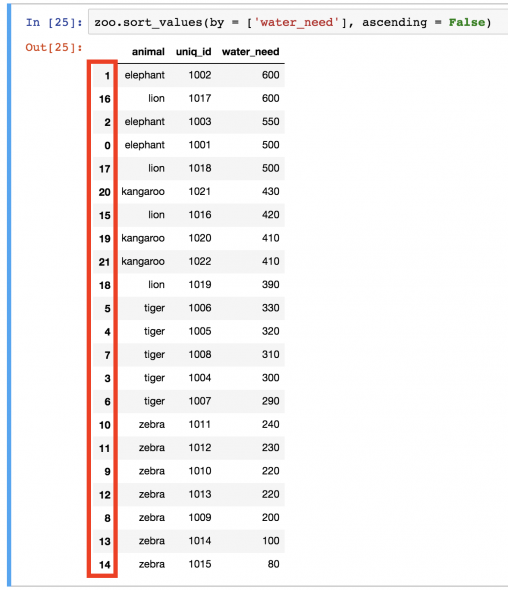
Это не просто не очень красиво смотрится. Если индексация выполняется неправильно, то качество визуализации может значительно ухудшиться. Или же могут нарушиться модели машинного обучения. Если изменяется DataFrame, может понадобиться осуществить реиндексирование строк. Для этого применяется метод reset_index(). Например.
zoo.sort_values(by=['water_need'], ascending=False).reset_index()
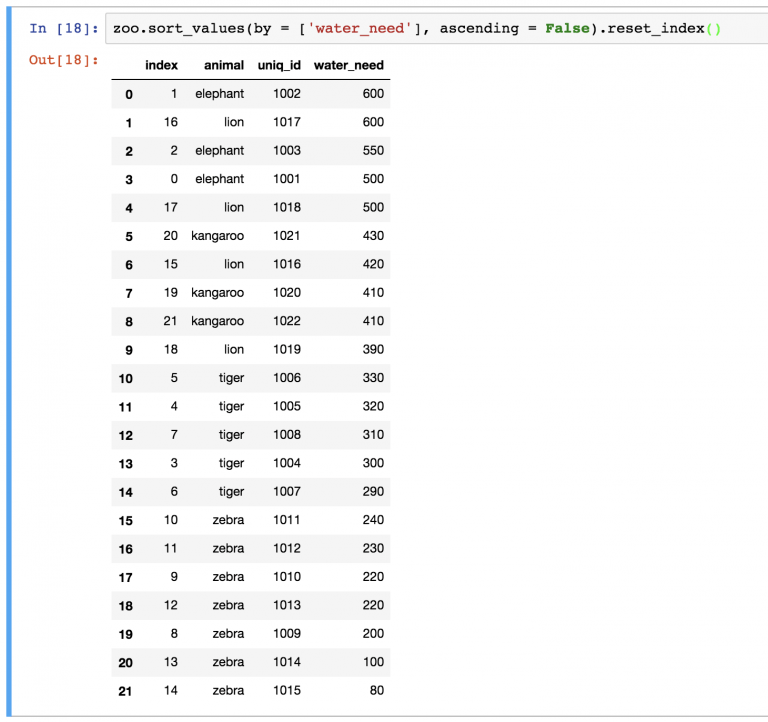
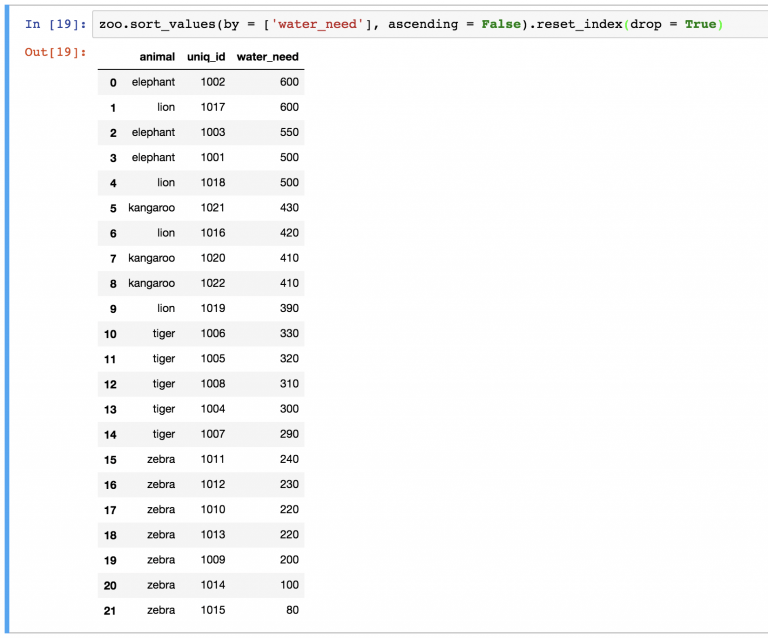
Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True)
Fillna
Давайте попробуем повторно запустить метод left-merge.
zoo.merge(zoo_eats, how='left')
Все это – перечень животных. Здесь есть одна проблема. Для львов значение NaN. Лучше его заменить на что-то более осмысленное. Например, на слово «unknown». Тогда функция fillna() автоматически найдет и заменит все значения NaN в DataFrame.
zoo.merge(zoo_eats, how='left').fillna('unknown')
Выводы
Таким образом, мы разобрались, как выполнять сортировку и объединение данных в pandas. Как видим, нет в этом ничего настолько сложного, как может показаться на первый взгляд. Чтобы понять материал этого урока лучше, рекомендуем самостоятельно писать весь код и адаптировать его под разные задачи.













