Любая информация доносится значительно проще, если она представлена визуально. Чтобы сделать обработку данных значительно проще, существует библиотека Pandas. Для визуализации данных с помощью метода .plot(), Даже если библиотека pandas только впервые начинает вами изучаться, уже через совсем небольшой промежуток времени вы сможете легко создавать графики с той информацией, которая вам будет нужной. А теперь мы более подробно поговорим о том, как осуществляется работа с этой библиотекой. Не все так сложно, как может показаться на первый взгляд. Мы разберем как теорию, так и примеры кода для большей наглядности.
Настройка среды в Python
Рекомендуется для разбора этой темы использовать Jupyter Notebook. Так появляется возможность увидеть графики непосредственно и проводить разнообразные эксперименты с ними. Помимо этого, потребуется виртуальная среда Python, в которой есть библиотека Pandas? Но какие действия нужно предпринимать, если у вас она не установлена? В этом случае необходимо воспользоваться одним из этих вариантов:
- Если задумка масштабная, то можно установить дистрибутив Anaconda, размером в пол гигабайта. Да, конечно его размер не подойдет тем, кто не имеет много места на жестком диске, но он дает возможность получить доступ к целому спектру инструментов, предназначенных для обработки данных.
- Если вы желаете использовать pip, то инсталлируйте соответствующие библиотеки с использованием инструкции pip install pandas matplotlib. Что касается Jupyter Notebook, то установить его можно с помощью команды pip install jupyterlab.
- Если вам требуется лишь попробовать код, то достаточно воспользоваться браузерной версией Jupyter Notebook. Для начинающего этот вариант является наиболее подходящим.
После того, как вы настроите среду, появляется возможность скачать тестовый набор с данными. Сегодня мы проведем анализ информации о специальностях, уровне дохода людей, которые закончили эти профессии.
Для начала нам скачать соответствующие сведения. Для этого необходимо воспользоваться pandas.read_csv, чтобы передать этому методу URL, с которого будут получены данные. Приложение, которое будет нами написано, само сможет получить соответствующую информацию.
In [1]: import pandas as pd In [2]: download_url = ( ...: "https://raw.githubusercontent.com/fivethirtyeight/" ...: "data/master/college-majors/recent-grads.csv" ...: ) In [3]: df = pd.read_csv(download_url) In [4]: type(df) Out[4]: pandas.core.frame.DataFrame
После осуществления нами вызова read_csv() происходит создание DataFrame. Эта структура данных, которая применяется в pandas, используется наиболее часто. Можно сказать, что она является основной.
Это руководство может быть вами использовано даже в случае, если вы ничего не знаете о структуре DataFrame. Тем не менее, для большего понимания вопроса все же лучше изучить ее. Ведь для работы с данными это все равно понадобится.
Если есть структура DataFrame, то можно проанализировать данные. Для этого необходимо осуществить настройку параметра display.max.columns, чтобы удостовериться, что не происходит скрытия никаких колонок. После этого, мы воспользуемся методом head(), чтобы посмотреть на первые несколько столбцов с данными.
In [5]: pd.set_option("display.max.columns", None)
In [6]: df.head()
С помощью этого кода можно отобразить пять строк. Тем не менее, с помощью аргумента функции df.head() можно выбрать любое их количество. Например, если нам надо показать десять штук, необходимо написать df.head(10).
Как создать простой график в Pandas?
Указанный набор данных включает несколько колонок, которые указывают на доходы людей, получившую каждую из этих специальностей.
- Median. Отображает средний заработок работников, занятых полным рабочим днем круглый год.
- P25th – 25-й процентиль.
- P75h – 75-й процентиль.
- «Rank» – рейтинг специалиста по среднему заработку.
Давайте попробуем создать график, отражающий эти колонки. Сперва необходимо осуществить настройку Jupyter Notebook так, чтобы он показывал диаграммы с использованием команды %matplotlib. Для демонстрации того, как это делается, приводим следующий код.
In [7]: %matplotlib Using matplotlib backend: MacOSX
С помощью этой команды мы настраиваем Jupyter Notebook таким образом, чтобы использовалась Matplotlib для показа графиков. По стандартным настройкам, предусматривается использование стандартного бэкенда от Matplotlib, а все графики будут отображаться в специальном окне.
К слову, бэкэнд Matplotlib может быть изменен путем передачи аргумента в специальную команду %matplotlib.
Например, бэкэнд inline активно используется в Jupyter Notebooks, так как он показывает график в самом блокноте непосредственно под ячейкой, создающей график.
In [7]: %matplotlib inline
Теперь вы подготовлены к тому, чтобы создать первый график. Чтобы это сделать, необходимо воспользоваться методом plot().
In [8]: df.plot(x="Rank", y=["P25th", "Median", "P75th"]) Out[8]: <AxesSubplot:xlabel='Rank'>
С помощью этого метода осуществляется возврат линейного графика, содержащего информацию из каждой строки структуры DataFrame. Что касается значений по оси x, то они представляют данные о рейтинге учеников. А на оси Y графика будут отображаться колонки, указывающие на место специалиста в определенном процентиле.
Возможно, вам понадобится интерфейс pyplot из mathplotlib. Это надо будет, если вы не используете IPython либо Jupyter Notebook.
Если используется стандартная оболочка Python, отображение графика должно осуществляться так:
>>> import matplotlib.pyplot as plt >>> df.plot(x="Rank", y=["P25th", "Median", "P75th"]) >>> plt.show()
Учтите, что перед вызовом plt.show(), чтобы отобразить график, необходимо осуществить импорт модуля pyplot из Matplotlib.
Наш график, который мы создали с использованием .plot(), как говорилось ранее отобразится отдельно. Он выглядит так.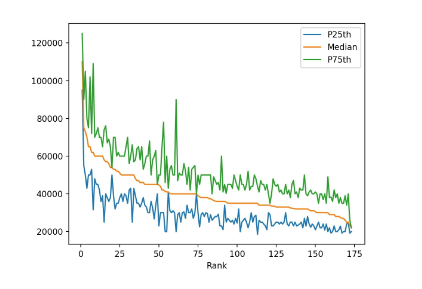
Какие можем сделать выводы в процессе рассмотрения этого графика?
- Величина среднего заработка становится меньше по мере того, какой рейтинг. Чем он меньше, тем и средний доход меньше. В целом, здесь нет ничего удивительного, учитывая то, что именно средний доход и определяет рейтинг.
- По ряду профессий, разрыв между 25-м и 75-м процентилями чрезмерно большой. Это говорит о том, что на фоне среднего дохода они могут зарабатывать или сильно меньше, либо сильно больше.
- Разрыв других специальностей между 25-м и 75-м процентилями очень маленький. Таким образом, заработная плата таких людей приближается к средней.
С помощью первого графика понимаем, что в датасетах находится большое количество привлекательной информации. У ряда профессий диапазон заработков очень большой. У других же он довольно маленький.
Как обнаружить эти различия? Приведенный выше график для этой цели не подходит. Необходимо использовать другие типы.
Метод plot() имеет ряд опциональных аргументов. Так, если нам необходимо определить тип создаваемого графика, необходимо воспользоваться параметром kind. Он может принимать одну из одиннадцати строк для того, чтобы задать тип графика. Сами они такие.
- area для графиков с накоплением;
- bar для вертикальной гистограммы;
- barh для горизонтальной гистограммы;
- box для графиков с боксами;
- hexbin для шестнадцатеричных графиков;
- hist для гистограмм;
- kde для графика оценки плотности ядра;
- density является альтернативным названием для kde;
- line для линейных графиков;
- pie для круговых графиков;
- scatter для графиков рассеяния.
Стандартный график – это line. Он используется по умолчанию. Это неплохой тип, который позволяет получить большое количество информации. Так, они нередко используются для обнаружения тенденций, которые действуют в целом. Конечно, они не подходят для глубинного анализа, но при этом позволяют выделить проблемные области.
Итак, если для метода plot() не использовать параметр, будет создан график линейного типа с индексом по оси x и всеми числовыми столбцами по y. Этот вариант подходит для обработки информации с несколькими столбцами.
Тем не менее, в нашем случае он подходит довольно плохо, поскольку визуально данные выглядят очень беспорядочно.
Особенности работы с библиотекой Matplotlib в Python
Когда мы вызываем метод plot() для DataFrame, описанная библиотека создает график. В этом можно удостовериться, если запустить такой фрагмент кода.
In [9]: import matplotlib.pyplot as plt In [10]: plt.plot(df["Rank"], df["P75th"]) Out[10]: [<matplotlib.lines.Line2D at 0x7f859928fbb0>]
Здесь сперва осуществляется импорт модуля mathplotlib.pyplot, а потом он переименовывается в plt. После этого осуществляется вызов метода plot() и выполняется передача колонки Rank объекта DataFrame в качестве первого аргумента. Помимо этого, колонка P75th передается в качестве второго.
В результате, мы получаем такой график.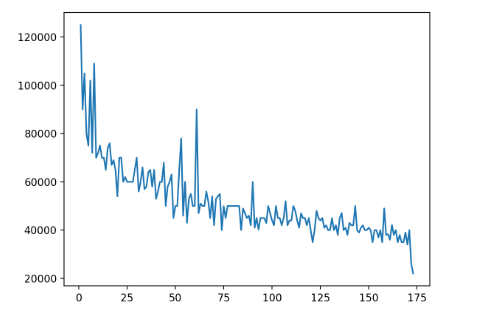
Выводы
Мы разобрали базовые аспекты создания графиков в Pandas. Тем не менее, это не все, конечно же. Но любое обучение необходимо начинать с малых шагов, а потом уже наращивать знания. Поэтому, чтобы вы не перегружались информацией, мы попробуем разобраться в других аспектах работы с этой библиотекой в следующий раз.
Настоятельно рекомендуется потренироваться перед тем, как воплощать полученные знания в жизнь. Задача любого обучения – довести нужные навыки до автоматизма. Поэтому обязательно попробуйте изменить описанный выше код под ваши задачи.













