Pandas – функциональная библиотека выполнения анализа различных типов данных. Она дает возможность выполнять множество операций, в том числе, и с графиками. Сегодня пойдет речь о том, как анализировать данные с их помощью, как реализовать распределения в Pandas, а также выполнять ряд других действий. Например, мы поговорим о том, как правильно строить гистограммы с помощью этой библиотеки.
Получение информации с помощью графиков в Python
С использованием графиков, которые мы рассмотрим далее, мы получим более подробное представление о наборе данных. Сперва мы рассмотрим распределение собственности с использованием гистограммы, после чего познакомимся с некоторыми инструментам для исследования выбросов.
Распределения и гистограммы
Чтобы работать с методом .plot(), недостаточно класса DataFrame. Объект Series, который также встречается в Pandas довольно часто, по функциональности работает схожим образом.
У вас есть возможность каждый столбец из DataFrame представить в виде объекта этого класса. Давайте теперь попробуем продемонстрировать, как правильно использовать колонку «Median» из структуры DataFrame, в основу которой легли специальности колледжей.
In [12]: median_column = df["Median"] In [13]: type(median_column) Out[13]: pandas.core.series.Series
Если есть объект Series, базируясь на нем, можно построить другой график – гистограмму. Она – прекрасный инструмент визуализации распределения значений по данным. Значения в гистограммах разбиваются на интервалы, и они показывают количество данных, которые есть в конкретном диапазоне.
Предположим, нам надо создать гистограмму для колонки «Median». Как это сделать?
In [14]: median_column.plot(kind="hist") Out[14]: <AxesSubplot:ylabel='Frequency'>
Здесь нами вызывается функция .plot() для median_column, после чего строка hist передается параметру kind. На этом все.
Когда мы пытаемся вызвать метод .plot(), то будет отображена следующая фигура.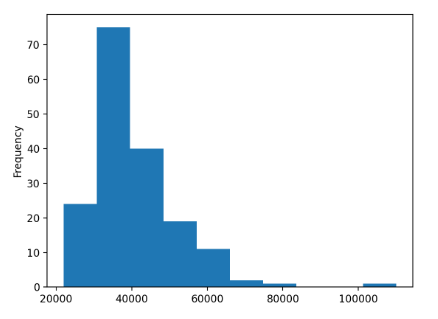
Гистограммой отображается информация, находящаяся в интервалах от 20 до 120 тысяч долларов. Всего их десять штук. По форме график не похож на тот, который должен быть при нормальном распределении. У него нет симметричности.
Выбросы в гистограмме
Скорее всего, вы увидели небольшой прямоугольник справа распределения. Такое ощущение, что некоторая информация может быть отнесена к определенной категории. Люди, работающие в этой отрасли получают прекрасную заработную плату, сравнивая как со средним уровнем дохода, так и с той, которая заняла второе место. Давайте этот выброс проанализируем. Для этого необходимо ответить на следующие вопросы.
- Какие профессии отражает он?
- Какая у него граница?
В этом случае мы можем сравнивать исключительно несколько пунктов. Гистограмма – прекрасный инструмент для этого. Сперва нам необходимо выбрать пять специальностей, где средний доход самый большой.
Необходимо два действия сделать.
- Отсортировать колонку «Median», применив метод .sort_values(), введя название колонки, которую надо отсортировать. Что касается порядка сортировки, то его нужно установить на ascending=False.
- Получить пять первых элементов списка с помощью метода .head().
Создадим еще одну структуру DataFrame, который будет называться top_5.
In [15]: top_5 = df.sort_values(by=»Median», ascending=False).head()
Теперь у нас есть структура DataFrame, не такого большого размера. В ней есть лишь пять профессий, доход по которым наиболее высокий. Далее мы можем построить диаграмму, где будут отображаться исключительно данные об основных специалистах, у которых 5 самых высоких средних зарплат.
In [16]: top_5.plot(x="Major", y="Median", kind="bar", rot=5, fontsize=4) Out[16]: <AxesSubplot:xlabel='Major'>
Внимание! Параметры rot и fontsize нужны, чтобы вращать и изменять размер ярлыков оси x, чтобы добиться их видимости. После этого перед нами появится график, в котором есть пять колонок.
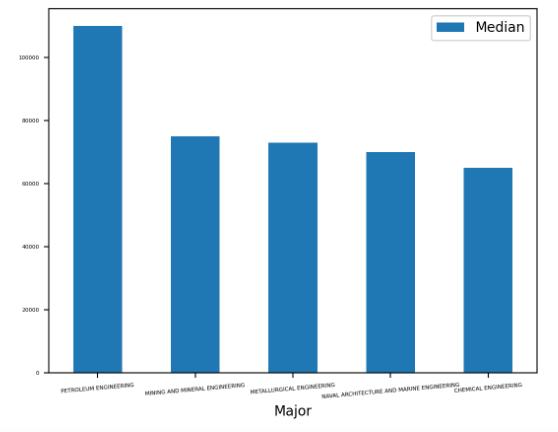
Исходя из него, мы можем увидеть, что средняя зарплата в углеводородной отрасли выше, чем у остальных, более, чем на 20 тысяч долларов. Что касается доходов профессий, находящихся на местах со второго по четвертое, располагаются сравнительно недалеко друг от друга относительно первой колонки слева.
Если вы имеете точку данных со значениями, которые будут более высокими либо низкими по сравнению с остальными, то, с высокой долей вероятностью, вам потребуется более детально ее изучить.
Давайте теперь проанализируем профессии, в которых средняя заработная плата находится на уровне выше, чем 60 тысяч долларов. Сперва надо осуществить фильтрацию базовых категорий, используя маску df[df[«Median»] > 60000]. После этого, мы создадим еще одну диаграмму, которая будет демонстрировать все три колонки с категориями доходов.
In [17]: top_medians = df[df["Median"] > 60000].sort_values("Median")
In [18]: top_medians.plot(x="Major", y=["P25th", "Median", "P75th"], kind="bar")
Out[18]: <AxesSubplot:xlabel='Major'>
После того, как вы запустите этот код, перед вами отобразится график с тремя колонками на каждую сферу деятельности.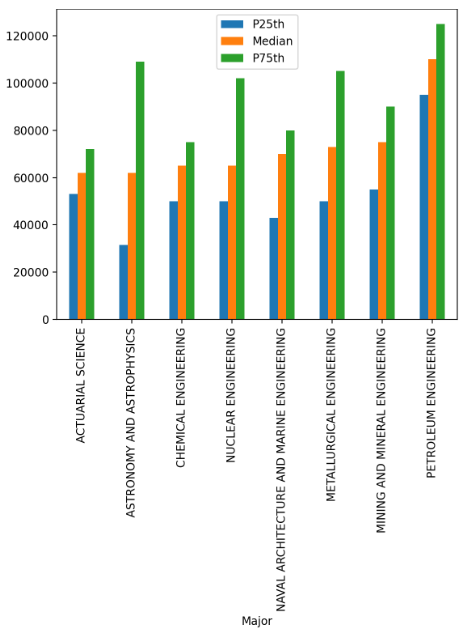
Мы можем подтвердить то, что сказано ранее, по 25-му и 75-му процентилю. Люди, которые получили образование в области нефтяной инженерии, получают самые высокие доходы.
По какой причине нам так важны выбросы здесь? Дело в том, что абитуриенты, когда выбирают профессию, исходят из определенной логики. Тем не менее, с точки зрения анализа такие выбросы нам также интересны. Они могут указывать не только лишь на доходные отрасли, но и на поврежденные данные. Это такая информация, которая вызывается человеческим фактором или техническими ошибками.
Например, может отказать датчик, произойти проблема при ручном вводе данных либо участие ребенка дошкольного возраста в фокус-группе, предназначенной для детей, которым исполнилось 10 лет и старше.
Допустим, вами проводится анализ информации о том, какие продажи у небольшого издателя. Вами выполняется группировка доходов по регионам, и они сравниваются за аналогичными за предыдущий период.
После этого издателем выпускается книга, которая становится популярной. В результате, продажи везде будут расти с учетом того, что вышел бестселлер. Эта информация называется шумами. Если же эти данные анализировать без выброса, мы получим более важные сведения. Мы сможем понять, что в Нью-Йорке продажи выросли, а вот в Майами – упали. Это даст возможность получать реальную картину того, что происходит в исследуемой области.
Выполнение проверки корреляции данных
Нередко ставится задача проанализировать степень взаимосвязи между двумя колонками с данными. Если вами будет выбрана специализация с более высоким средним доходом, то какая вероятность будет остаться без работы вообще? Для этого необходимо создать диаграмму рассеяния, в которой будут следующие колонки.
In [19]: df.plot(x="Median", y="Unemployment_rate", kind="scatter") Out[19]: <AxesSubplot:xlabel='Median', ylabel='Unemployment_rate'>
В результате, появится график, напоминающий следующий.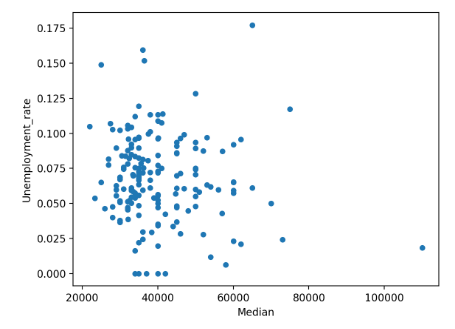
Если мы быстро посмотрим на эту фигуру, то обнаружим, что между безработицей и уровнем заработка корреляции здесь нет.
Этот инструмент прекрасно подходит для того, чтобы получить предварительную информацию о том, какие возможны взаимосвязи. Тем не менее, он не служит доказательством того, что такая корреляция присутствует.
Чтобы проанализировать корреляцию между колонками, необходимо использовать метод .corr().
Анализ категориальных данных
А что, если нам надо обрабатывать большие массивы данных за раз? В этом случае лучше выполнять сортировку. Конечно, этот прием неидеальный. Тем не менее, он работает.
Группировка данных в Pandas
Категории, как правило, нужны для группировки данных и их агрегирования. Для этого необходимо воспользоваться методом .groupby().
In [23]: small_cat_totals = cat_totals[cat_totals < 100_000] In [24]: big_cat_totals = cat_totals[cat_totals > 100_000] In [25]: # Adding a new item "Other" with the sum of the small categories In [26]: small_sums = pd.Series([small_cat_totals.sum()], index=["Other"]) In [27]: big_cat_totals = big_cat_totals.append(small_sums) In [28]: big_cat_totals.plot(kind="pie", label="") Out[28]: <AxesSubplot:>
Нами был добавлен аргумент label=””. По умолчанию, pandas добавляет отметку, содержащую название колонки. В нашем случае это не нужно.
После того, как вы запустите этот код, получим такую диаграмму.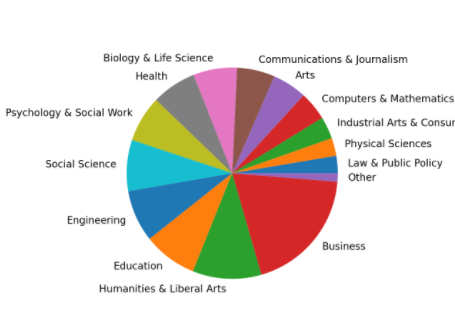
В нашем случае категория Other все еще маленькая. Это хорошо. Это говорит о том, что решение о том, чтобы объединить маленькие категории, было правильным.
Анализ данных внутри категории
В некоторых случаях нам необходимо убедиться в том, что категоризация определенного типа действительно имеет смысл. Например, являются элементы категории более похожими друг на друга, чем на остальную часть набора данных.
Давайте создадим гистограмму, которая демонстрирует, как распределяется средний доход для инженерных профессий.
In [29]: df[df["Major_category"] == "Engineering"]["Median"].plot(kind="hist") Out[29]: <AxesSubplot:ylabel='Frequency'>
После того, как мы это сделаем, нами будет получена гистограмма, которая может быть сравнена с той, которая была в самом начале.
Заключение
Таким образом, мы разобрались, как правильно визуализировать данные с использованием библиотеки Pandas. Графики могут очень много, как видим.













